ComfyUI-Realtime-Lora
Описание
Train LoRAs directly inside ComfyUI for Z-image Turbo, SDXL, Flux, WAN 2.2, SD 1.5
Языки
- Python90,7%
- JavaScript9,3%
ComfyUI Realtime LoRA Toolkit
![]()
![]()
Train, analyze, and selectively by Block load LoRAs for SDXL, SD 1.5, FLUX, Z-Image, Qwen Image, Qwen Image Edit, and Wan 2.2 directly inside ComfyUI. One unified interface across three training backends, plus powerful analysis and block-level loading tools.
New in v1.1: LoRA Analysis & Selective Block Loading - See which blocks matter and load only the ones you want!
Capture a face, a style, or a subject from your reference images and apply it to new generations - all within the same workflow. No config files. No command line. Just connect images and go.
At a Glance
| Backend | Models | Best For |
|---|---|---|
| sd-scripts | SDXL, SD 1.5 | Fast training, mature workflows, broad checkpoint compatibility |
| Musubi Tuner | Z-Image, Qwen Image, Qwen Image Edit, Wan 2.2 | Cutting-edge models, smaller LoRAs, excellent VRAM efficiency |
| AI-Toolkit | FLUX.1-dev, Z-Image, Wan 2.2 alternative training pipeline |
7 architectures. 3 training backends. 8 trainer nodes. 5 selective loaders. 1 analyzer.
Use Cases
- Subject consistency - Train on a character or face, use across multiple generations
- Style transfer - Capture an art style from a few reference images
- Rapid prototyping - Test a LoRA concept in minutes before committing to longer training
- Video keyframes - Train on first/last frames for Wan video temporal consistency
- Image editing behaviors - Use Qwen Image Edit to teach specific transformations with paired images
What This Does
This node trains LoRAs on-the-fly from your images without leaving ComfyUI. SDXL and SD 1.5 training is particularly fast - a few minutes on a decent GPU, or under 2 minutes for SD 1.5 on modern hardware. This makes it practical to train a quick LoRA and immediately use it for img2img variations, style transfer, or subject consistency within the same workflow.
Personal note: I think SDXL is due for a revival. It trains fast, runs on reasonable hardware, and the results are solid. For quick iteration - testing a concept before committing to a longer train, locking down a subject for consistency, or training on frames for Wan video work - SDXL hits a sweet spot that newer models don't always match. Sometimes the "old" tool is still the right one.
Supported Models
Via Kohya sd-scripts:
- SDXL (any checkpoint) - tested with Juggernaut XL Ragnarok, base SDXL will work too
- SD 1.5 (any checkpoint) - blazingly fast, ~2 mins for 500 steps on a 5090
Via Musubi Tuner:
- Z-Image - faster training, smaller LoRA files, no diffusers dependency. Requires the de-distilled model for training, but trained LoRAs work with the regular distilled Z-Image Turbo model.
- Qwen Image - text-to-image generation. Supports Qwen-Image, Qwen-Image-Edit, and Qwen-Image-Edit-2509 models for style/subject LoRAs.
- Qwen Image Edit - for training image editing behaviors with source/target image pairs. Uses folder paths for paired training data.
- Wan 2.2 - single-frame image training with High/Low/Combo noise modes. Separate block offloading control for fine-tuned VRAM management.
Via AI-Toolkit:
- Z-Image Turbo
- FLUX.1-dev
- Wan 2.2 (High/Low/Combo)
Note on Wan 2.2 modes: Wan uses a two-stage noise model - High handles early denoising steps, Low handles later steps. You can train separate LoRAs for each, or use Combo mode which trains a single LoRA across all noise steps that works with both High and Low models.
Technical note: When using High or Low mode, the example workflows still pass the LoRA to both models but at zero strength for the one you didn't train. This prevents ComfyUI from loading the base model into memory before training starts - a workaround to avoid unnecessary VRAM usage.
Requirements
JUST WANT TO ANALYZE OR SELECTIVELY LOAD LORAS?
The LoRA Analyzer and Selective Loaders work out of the box - no additional installation required!
The training backend requirements below ONLY apply if you want to train LoRAs. Skip this section if you're just using the analysis and selective loading features.
Python version: Both AI-Toolkit and sd-scripts work best with Python 3.10-3.12. Python 3.10 is the safest bet. Avoid 3.13 for now.
For training nodes only - install the backend(s) you need:
For SDXL / SD 1.5 training:
- Install sd-scripts: https://github.com/kohya-ss/sd-scripts
- Follow their install instructions
For Musubi Tuner models (Z-Image, Qwen Image, Wan 2.2):
-
Install Musubi Tuner: https://github.com/kohya-ss/musubi-tuner
-
Follow their install instructions
-
Download the required models:
Z-Image: Download the de-distilled model from https://huggingface.co/ostris/Z-Image-De-Turbo/tree/main - save to
Qwen Image: Download bf16 models (not fp8) from Comfy-Org or from the links in the exampe workflows:
- DiT: https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI (qwen_image_bf16.safetensors) or https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI for Edit models
- VAE: qwen_image_vae.safetensors
- Text Encoder: qwen_2.5_vl_7b.safetensors (from clip folder)
- Note: Pre-quantized fp8 models don't work for training - use bf16 versions.
Wan 2.2: Download fp16 models from Comfy-Org or from the links in the exampe workflows:
- DiT: wan2.2_t2v_14B_fp16.safetensors (High or Low noise variant)
- VAE: wan_2.2_vae.safetensors
- T5: models_t5_umt5-xxl-enc-bf16.pth
For FLUX/Z-Image/Wan training (AI-Toolkit):
- Install AI-Toolkit: https://github.com/ostris/ai-toolkit
- Follow their install instructions
RTX 50-series GPUs (AI-Toolkit only): Blackwell GPUs (RTX 5080/5090) require PyTorch 2.7+ with CUDA 12.8 support. The standard AI-Toolkit installation may not work out of the box. A community installer is available at https://github.com/omgitsgb/ostris-ai-toolkit-50gpu-installer that handles the correct PyTorch/CUDA versions. Note: sd-scripts for SDXL/SD1.5 training & Musubi Training is unaffected - this applies only to AI-Toolkit.
You don't need to open the training environments after installation. The node just needs the path to where you installed them.
Installation
Clone this repo into your ComfyUI custom_nodes folder:
cd ComfyUI/custom_nodes
git clone https://github.com/ShootTheSound/comfyUI-Realtime-Lora
Restart ComfyUI.
Nodes
Search for these in ComfyUI:
- Realtime LoRA Trainer - Trains using AI-Toolkit (FLUX, Z-Image, Wan)
- Realtime LoRA Trainer (Z-Image - Musubi Tuner) - Trains Z-Image using Musubi Tuner (recommended)
- Realtime LoRA Trainer (Qwen Image - Musubi Tuner) - Trains Qwen Image/Edit models for style/subject LoRAs
- Realtime LoRA Trainer (Qwen Image Edit - Musubi Tuner) - Trains edit behaviors with source/target image pairs
- Realtime LoRA Trainer (Wan 2.2 - Musubi Tuner) - Trains Wan 2.2 with High/Low/Combo noise modes
- Realtime LoRA Trainer (SDXL - sd-scripts) - Trains using sd-scripts (SDXL)
- Realtime LoRA Trainer (SD 1.5 - sd-scripts) - Trains using sd-scripts (SD 1.5)
- Apply Trained LoRA - Applies the trained LoRA to your model
Analysis & Selective Loading:
- LoRA Loader + Analyzer - Loads a LoRA and analyzes block-level impact (outputs analysis JSON for selective loaders)
- Selective LoRA Loader (SDXL) - Load SDXL LoRAs with per-block toggles and strength sliders
- Selective LoRA Loader (Z-Image) - Load Z-Image LoRAs with per-layer toggles (30 layers)
- Selective LoRA Loader (FLUX) - Load FLUX LoRAs with per-block toggles (57 blocks: 19 double + 38 single)
- Selective LoRA Loader (Wan) - Load Wan LoRAs with per-block toggles (40 blocks)
- Selective LoRA Loader (Qwen) - Load Qwen LoRAs with per-block toggles (60 blocks)
Getting Started
There are critical example workflows with useful info included in the custom_nodes/comfyUI-Realtime-Lora folder. Open one in ComfyUI and:
- Paste the path to your training backend installation (sd-scripts, Musubi Tuner, or AI-Toolkit)
- For SDXL/SD1.5: select your checkpoint from the dropdown
- For Musubi Tuner Z-Image: select your de-distilled model, VAE, and text encoder from the dropdowns
- For AI-Toolkit models: the first run will download the model from HuggingFace automatically
First run with AI-Toolkit: The model will download to your HuggingFace cache folder. On Windows this is
Basic Usage
- Add the trainer node for your model type
- Connect your training image(s)
- Set the path to your training backend installation
- Queue the workflow
- Connect the lora_path output to the Apply Trained LoRA node
Features
- Train from 1 to 100+ images
- Per-image captions (optional)
- Folder input for batch training with .txt caption files
- Automatic caching - identical inputs skip training and reuse the LoRA
- VRAM presets for different GPU sizes
- Settings are saved between sessions
LoRA Analysis & Selective Loading
Beyond training, this toolkit includes tools for understanding and fine-tuning how LoRAs affect your generations.
▶ Watch Demo: LoRA Analysis & Selective Block Loading
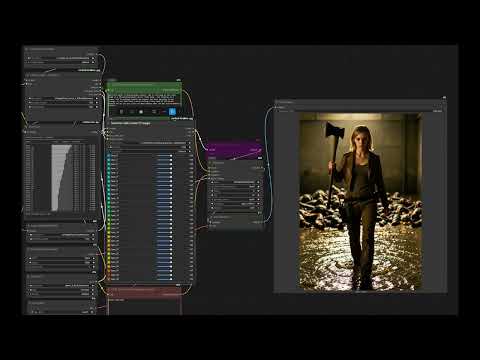
LoRA Loader + Analyzer
The analyzer loads any LoRA and shows you which blocks have the most impact. It calculates a "strength" score (0-100%) for each block based on the weight magnitudes in that block. High-impact blocks are where the LoRA learned the most - these are often the blocks responsible for the subject's face, style, or composition.
Outputs:
Selective LoRA Loaders
Each architecture has its own selective loader with toggles and strength sliders for every block or layer. This lets you:
- Disable low-impact blocks to reduce LoRA influence on parts of the image
- Focus on specific blocks (e.g., face blocks, style blocks, composition blocks)
- Fine-tune strength per-block instead of using a single global strength
Presets included:
- Default (all on at 1.0)
- All Off
- Half Strength
- Architecture-specific presets (High Impact, Face Focus, Style Only, etc.)
Impact-Colored Checkboxes
Connect the
- Blue = Low impact (0-30%)
- Cyan/Green = Medium impact (30-60%)
- Yellow/Orange = High impact (60-90%)
- Red = Very high impact (90-100%)
This makes it easy to see at a glance which blocks matter most for your LoRA.
Usage Notes
-
Analyzer standalone: The LoRA Loader + Analyzer works on its own as a drop-in replacement for ComfyUI's standard LoRA loader. The analysis outputs are optional - you can ignore them and just use the model/clip outputs.
-
Path override: When you connect a path to a Selective Loader's
-
Trainer → Selective Loader: The
Defaults (Z-Image example)
- 400 training steps
- Learning rate 0.0002
- LoRA rank 16
- Low VRAM mode (768px)
These defaults are starting points for experimentation, not ideal values. Every subject and style is different.
Learning rate advice:
- 0.0002 trains fast but can overshoot, causing artifacts or burning in the subject too hard
- Try lowering to 0.0001 or 0.00005 for more stable, gradual training
- If your LoRA looks overcooked or the subject bleeds into everything, lower the learning rate
- If your LoRA is too weak after 400-500 steps, try more steps before raising the learning rate, its already high in the example workflows.
Support
If this tool saves you time or fits into your workflow, consider buying me a coffee.
I'm currently between contracts due to family circumstances, which has given me time to build and maintain this project. Your support helps me keep developing it.
No perks, no tiers - just a way to say thanks if you find it useful.
Credits
This project makes use of these excellent training tools fro the training nodes:
- AI-Toolkit by ostris: https://github.com/ostris/ai-toolkit
- sd-scripts by kohya-ss: https://github.com/kohya-ss/sd-scripts
- Musubi Tuner by kohya-ss: https://github.com/kohya-ss/musubi-tuner
The training is done by these projects. This node just makes them accessible from within ComfyUI in a user centric manner. Essentially i want to democratize training and make it easier to get into creativly.
Author
Peter Neill - ShootTheSound.com / UltrawideWallpapers.net
Background in music industry photography and video. Built this node to make LoRA training accessible to creators who just want to get things done without diving into command line tools.
Feedback is welcome - open an issue or reach out.
License
MIT