Amazing-Python-Scripts
..
/
Plagiarism-Checker
README.md
Plagiarism Checker
Introduction
- Plagiarism checking/detection is the identification of similarities between texts and establishing if one text is derived from another, and it may be used to spot situations of academic dishonesty or unauthorised copying.
- This code analyses the textual data and looks for possible instances of plagiarism using TF-IDF (Term Frequency-Inverse Document Frequency) vectorization and cosine similarity.
Prerequisites
- Install scikit-learn by: '$ pip install scikit-learn'
How it works
- There are four text documents in the repository.
- The paths to text files that are located in the same directory as the code file are loaded at the beginning of the code. It recognises and records the paths of all files with the .txt extension in the student_files list.
- Next, the code reads the contents of each text file and stores them in the student_notes list.
- The TfidfVectorizer class from scikit-learn is used by the vectorize function to perform TF-IDF vectorization on a list of text documents. The relative relevance of each term in a document in relation to the corpus of texts is captured by the TF-IDF, a numerical representation of textual data. The function returns arrays of numbers that represent the documents' TF-IDF vectors.
- The similarity function computes the cosine similarity between two document vectors. Cosine similarity measures the cosine of the angle between two vectors and is commonly used to compare the similarity of documents represented as vectors. The function returns the similarity score between the two input vectors.
- The code with the help of the vectorize function vectorizes the textual data, converting it to numerical arrays using TF-IDF representation.
- The vectorized data is then paired with their corresponding student files and stored in the s_vectors list.
- The check_plagiarism function compares the vectorized documents of each pair of students using cosine similarity. It iterates through each student's vector and compares it with the vectors of all other students. For each pair of students, it computes the similarity score using the similarity function and stores the student pair and their similarity score in the plagiarism_results set.
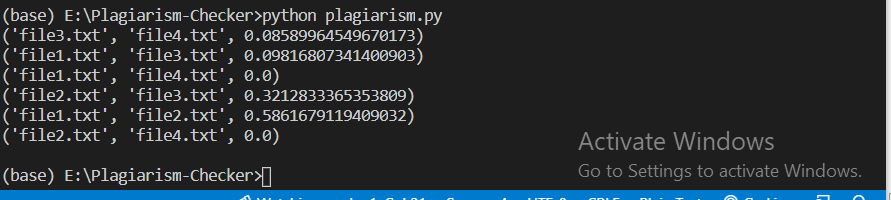
- And at last the code loops through the plagiarism_results set and prints the student pairings along with their similarity ratings.
- $ python plagiarism.py
Notes
- Please make sure the text files are readable and contain textual processable data.
- The text files must be in the same directory as the code file.
- If not need to provide the appropriate path in the student_files section of the code.
Screenshots